Présentation
AIMotions est une application web basée sur l’IA permettant à des étudiants de s’entraîner aux entretiens d’embauche. La plateforme soumet à l’utilisateur une question aléatoire de recruteur sur un domaine qu’il choisit, et l’invite à y répondre directement face caméra — comme en situation réelle.
Une fois l’enregistrement terminé, notre IA analyse la vidéo image par image et retourne un rapport détaillé des émotions détectées seconde par seconde : joie, stress, surprise, neutralité, etc. L’objectif est d’offrir un retour objectif sur le ressenti projeté pendant la réponse, sans intervention humaine.
Je me suis occupé avec mon équipe de l’intégralité de la partie backend : conception de l’API, pipeline d’analyse vidéo, intégration du modèle IA et gestion du stockage.
État de l’art & étude préalable
Avant de commencer le développement, nous avons mené une étude approfondie de l’existant pour cadrer nos choix techniques et valider la faisabilité du projet.
Concurrents et outils existants
Plusieurs solutions commerciales couvrent déjà la détection d’émotions faciales :
- Microsoft Azure Face API et Amazon Rekognition proposent des APIs cloud clé en main, mais impliquent un coût à l’usage et une dépendance forte à des services tiers — incompatible avec un projet académique autonome
- Affectiva (racheté par Smart Eye) est une référence dans l’analyse d’émotions en contexte automobile et publicitaire, avec des modèles très performants mais propriétaires
- OpenFace est une librairie open source académique capable d’extraire des Action Units (AU) du visage, mais sa prise en main est complexe et l’intégration dans un pipeline web peu documentée
Ce constat a confirmé qu’il existait un réel angle différenciant : combiner entraînement à l’entretien et feedback émotionnel automatisé, sans dépendance à un service cloud payant.
Contraintes de ressources
L’entraînement d’un CNN de cette taille sur ~28 000 images représente un coût computationnel non négligeable. Nous avons dû composer avec :
- Absence de GPU dédié : l’entraînement a été réalisé en environnement local, ce qui a contraint le nombre d’epochs et la taille des batchs testés
- Stockage et transfert vidéo : traiter des vidéos en temps réel côté serveur implique une gestion fine des fichiers temporaires — d’où le choix de Supabase pour externaliser le stockage et éviter de saturer le serveur
- Fréquence d’analyse : analyser chaque frame aurait été trop coûteux ; nous avons calibré à 2 prédictions par seconde, ce qui offre un bon compromis entre précision temporelle et charge CPU
Fonctionnalités
- Sélection d’un domaine et tirage aléatoire d’une question de recruteur
- Enregistrement vidéo directement depuis le navigateur
- Analyse automatique des émotions image par image via un CNN
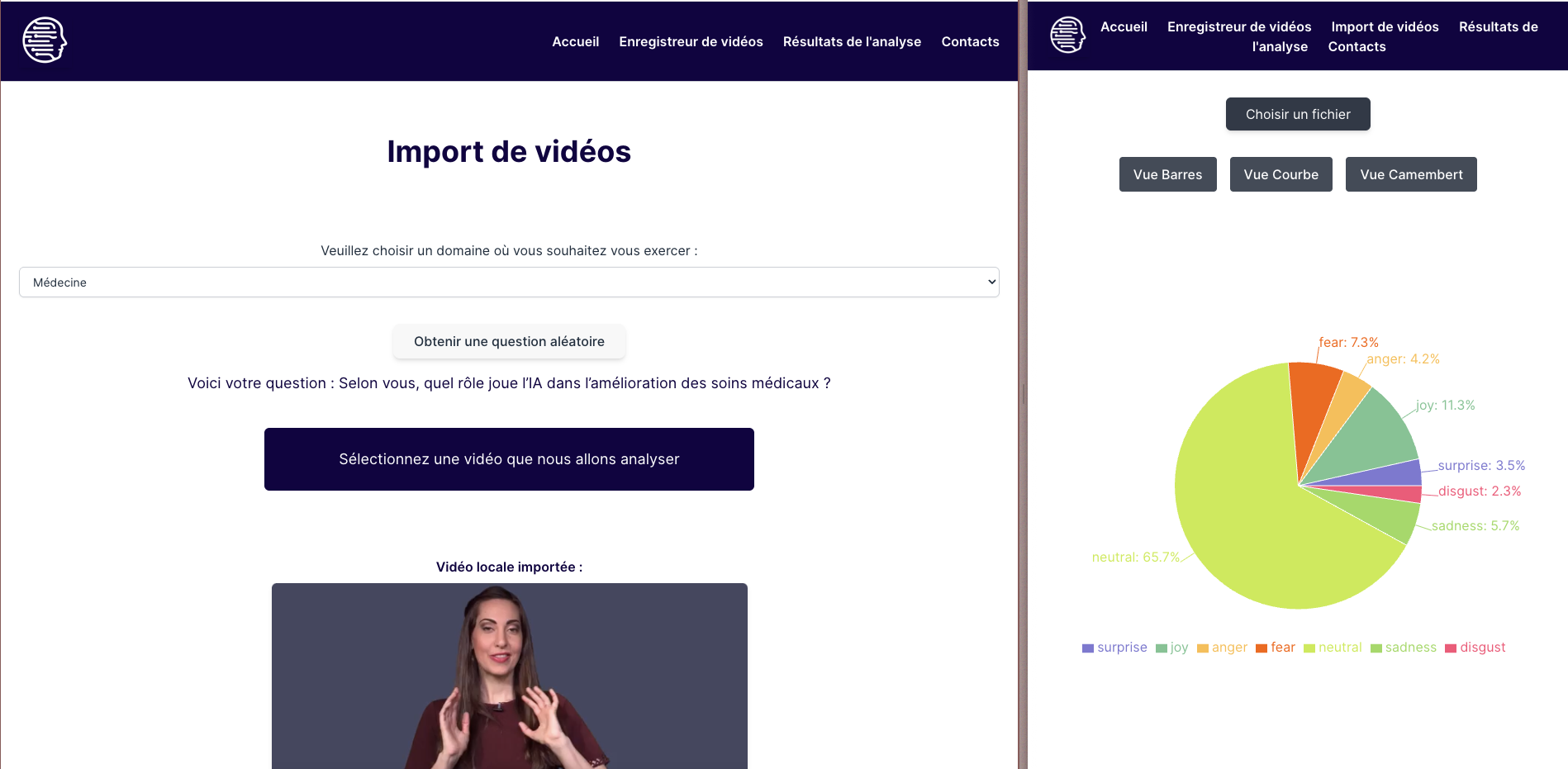
- Rapport visuel des émotions détectées seconde par seconde
- Vidéo annotée avec le rectangle de détection et l’émotion dominante affichée
Stack technique
Le backend est développé en Python 3.10 avec FastAPI comme framework REST et Uvicorn comme serveur ASGI. Le modèle est entraîné avec TensorFlow/Keras, et la détection de visage est assurée par OpenCV via le classifieur Haar Cascade. Les vidéos et fichiers CSV résultats sont stockés dans Supabase (bucket media).
Le pipeline fonctionne ainsi :
- Le frontend envoie la vidéo MP4 en
POST /document/upload-document - Le backend extrait chaque frame, détecte le visage, et applique le modèle 2 fois par seconde
- Les probabilités des 7 émotions sont enregistrées dans un CSV horodaté
- La vidéo annotée et le CSV sont uploadés sur Supabase
- L’URL du résultat est retournée au frontend
- Le retour sera traité via des graphiques
Intelligence Artificielle
Le modèle est un réseau de neurones convolutif (CNN) entraîné sur le Face Expression Recognition Dataset disponible sur Kaggle.
- Dataset : 28 821 images d’entraînement + 7 066 images de validation, réparties en 7 classes
- Classes : Colère, Dégoût, Peur, Joie, Neutre, Tristesse, Surprise
- Entrée : Images 48×48 pixels en niveaux de gris, normalisées entre 0 et 1
- Sortie : Vecteur de probabilités softmax sur 7 émotions
Architecture du modèle
Le modèle suit une architecture CNN séquentielle avec 4 blocs convolutifs progressifs :
- Conv2D(128) → MaxPool → Dropout(0.4)
- Conv2D(256) → MaxPool → Dropout(0.4)
- Conv2D(512) → MaxPool → Dropout(0.4)
- Conv2D(512) → MaxPool → Dropout(0.4)
- Flatten
- Dense(512) → Dropout(0.4)
- Dense(256) → Dropout(0.3)
- Dense(7, softmax)
Entraîné sur 30 epochs avec un batch size de 128 et l’optimiseur Adam (perte : categorical crossentropy).
Performances et limites
Le modèle atteint une accuracy correcte sur le jeu de validation, mais plusieurs limites sont à noter :
- Déséquilibre des classes : la classe dégoût ne compte que 436 images contre 7 164 pour joie, ce qui biaise les prédictions vers les émotions sur-représentées
- Overfitting potentiel : malgré les dropouts (0.3–0.4), un CNN à 4 blocs sur un dataset de taille modérée peut mémoriser des features trop spécifiques au train set
- Contraintes du Haar Cascade : la détection de visage est sensible aux conditions d’éclairage, aux angles de la tête et aux occlusions partielles (main devant le visage, etc.)
- Résolution d’entrée limitée : les images 48×48 en niveaux de gris induisent une perte d’information significative, notamment sur les micro-expressions